
1. XD2000への移行に向けたメモリ量測定について
XC50とXD2000に搭載されているメモリ量は以下になります。 XD2000では,特にシステムMにおいてメモリ量がコア当たりに換算して XC50のメモリ量の約10%となります。 またメモリを多く搭載しているシステムPでも,コア当たりに換算すると XC50の半分程度になります。
詳細はXD2000システムをご覧ください。
| ノード当たりのメモリ量 | コア当たりのメモリ量 | |
| XC50 | 384GB | 9.6GB |
| XD2000 システムM | 128GB | 1.14GB |
| XD2000 システムP | 512GB | 4.57GB |
XC50にはメモリが比較的潤沢に搭載されていたため,現在XC50で実行中の計算のメモリ消費量を把握しておられないユーザの方もおられると思います。 メモリ量が制限されたXD2000への円滑な移行のために, XC50で実行中の計算あるいはXD2000での実行を計画している計算の消費メモリを,事前に測定していただくようにお願いいたします。XD2000利用申請には,ノード時間積に加えてメモリ量の見積もりを記載していただくことになりました。
ここではXC50においてメモリ量を測定する2つの方法(CrayPatを使う方法と/proc/self/statusを使う方法)を紹介します。
後者の/proc/self/statusを使う方法は,OSがLinuxであればXC50でなくても使うことができます。
共にメモリ量のHigh Water Mark(最高水位)を出力しますが,/proc/self/statusに記載のVmHWMは,CrayPatの対応する値よりも大きくなることがあります。ファイル出力時に一時的に使用されるディスクキャッシュがカウントされているのが原因の一つとして考えられます。両者の値が大きく違う場合,アプリケーション自体が使用するメモリ量としては,CrayPatの方を参照してください。
CrayPatを使う方法
計算ノードは2つのNUMA(Non-Uniform Memory Access)ノード(それぞれ20 core搭載)で構成されています。
それぞれのNUMAノードに192GBのメモリが接続されています。
以下に示すのは,実行バイナリの名前を./a.outとした場合の例です。
適宜「./a.out」を自分の実行バイナリ名に置き換えてください。
- perftoolsをロード
- ソースコードを再コンパイルして,実行バイナリをpatバイナリ(a.out+pat)形式に変換
- CrayPatはオブジェクトファイル(*.o)を参照しますので,オブジェクトファイルを経由さずに直接実行バイナリを生成した状態でpatバイナリへ変換するとエラーとなります。
- また,再コンパイルせずに, pat_buildを実行すると,「ERROR: Missing required ELF section '.note.link' from the program (実行バイナリ). Load the correct 'perftools' module and rebuild the program.」というエラーが出ます。
- 大容量メモリを利用するプログラムの場合「 /usr/bin/ld: failed to convert GOTPCREL relocation; relink with --no-relax」というエラーが出ることがあります。リンクの際におこなわれるアドレス割り当ての最適化作業に必要なメモリ量が不足してしまうことが原因と考えられます。「 -Wl,--no-relax」をリンクの際に付けていただくと最適化を抑制します。
上の例ですと,「 $ cc -Wl,--no-relax -o ./a.out sample.o」です。 - aprunを使ってa.out+patをバッチジョブとして実行
- ディレクトリa.out+pat+PID+nodeIDsの生成
- レポートを生成
|
$ module load perftools |
再コンパイルする際は最適化オプションを外すことが推奨されています。
|
$ cc -c sample.c $ cc -o ./a.out sample.o $ pat_build ./a.out |
実行すると,a.out+patができます。「a.out」の部分は実行バイナリの名前に置き換わります。
注意点
以下は1ノードを使い,32プロセスで実行する例です。2つのNUMAノードにそれぞれ16プロセスを配分しています。
ジョブスクリプトでもperftoolsモジュールをロードしてください。
#!/bin/bash
#PBS -q debug
#PBS -l nodes=1
cd $PBS_O_WORKDIR
module load perftools
aprun -n 32 -S 16 ./a.out+pat
PIDとnodeIDsには何らかの数値が入ります。
|
$ pat_report -o sampling.txt a.out+pat+PID+nodeIDs |
上記はレポートファイル名をsampling.txtとした例です。sampling.txtの中でTable 6にメモリ使用量が記載されています。
HiMemは,Memory high water markの意味で最大メモリ使用量に対応します。
numanode.0とnumanode.1は,それぞれNUMAノード0とNUMAノード1に割り当てられたプロセスのメモリ使用量の平均値です。
下の例では,NUMAノード0に接続したメモリのプロセス当たりの使用量は330.3MBytesで,NUMAノード1に接続したメモリのプロセス当たりの使用量は315.3MBytesとなります。今回の計算では,各NUMAノードに16プロセス割り当てられているので,全メモリ使用量は,(330.3MBytes+315.3MBytes)x16コアで10.33GBytesとなります。
Table 6: Memory High Water Mark by Numa Node
Process | HiMem | HiMem | Numanode
HiMem | Numa | Numa | PE=HIDE
(MBytes) | Node 0 | Node 1 |
| (MBytes) | (MBytes) |
645.6 | 330.3 | 315.3 | Total
|-------------------------------------------
| 323.1 | 321.8 | 1.2 | numanode.0
| 322.6 | 8.5 | 314.1 | numanode.1
|===========================================
プロセス平均したメモリ使用量ではなく,各プロセスのメモリ使用量を出力するには,
|
$ pat_report -s pe=ALL -o sampling.txt a.out+pat+PID+nodeIDs |
を実行します。今回の例では,各プロセスに対し,ほぼ均等にメモリが割り当てられているので,メモリ使用量はプロセスでほぼ同じです。
Table 6: Memory High Water Mark by Numa Node
Process | HiMem | HiMem | Numanode
HiMem | Numa | Numa | PE
(MBytes) | Node 0 | Node 1 |
| (MBytes) | (MBytes) |
645.9 | 331.2 | 314.8 | Total
|-------------------------------------------
| 322.9 | 322.1 | 0.8 | numanode.0
||------------------------------------------
|| 323.1 | 322.2 | 0.9 | pe.0
|| 323.0 | 322.2 | 0.8 | pe.5
|| 323.0 | 322.2 | 0.8 | pe.3
|| 323.0 | 322.2 | 0.8 | pe.13
|| 322.9 | 322.2 | 0.8 | pe.6
|| 322.9 | 322.0 | 0.9 | pe.10
|| 322.9 | 322.1 | 0.8 | pe.9
|| 322.9 | 322.1 | 0.8 | pe.8
|| 322.8 | 322.1 | 0.7 | pe.4
|| 322.8 | 322.0 | 0.8 | pe.11
|| 322.8 | 321.9 | 0.9 | pe.14
|| 322.8 | 322.1 | 0.7 | pe.15
|| 322.7 | 321.9 | 0.8 | pe.12
|| 322.7 | 321.8 | 0.9 | pe.2
|| 322.7 | 321.9 | 0.8 | pe.7
|| 322.6 | 321.8 | 0.8 | pe.1
||==========================================
| 323.1 | 9.1 | 314.0 | numanode.1
||------------------------------------------
|| 323.2 | 9.3 | 313.9 | pe.30
|| 323.2 | 9.2 | 314.0 | pe.16
|| 323.2 | 9.1 | 314.1 | pe.21
|| 323.1 | 9.1 | 314.1 | pe.20
|| 323.1 | 9.1 | 314.1 | pe.27
|| 323.1 | 9.2 | 313.9 | pe.26
|| 323.1 | 9.0 | 314.1 | pe.22
|| 323.1 | 9.3 | 313.8 | pe.18
|| 323.1 | 9.2 | 313.8 | pe.19
|| 323.1 | 9.2 | 313.9 | pe.24
|| 323.1 | 9.0 | 314.0 | pe.23
|| 323.0 | 9.0 | 314.0 | pe.31
|| 323.0 | 9.0 | 314.0 | pe.28
|| 323.0 | 8.9 | 314.1 | pe.17
|| 323.0 | 9.0 | 313.9 | pe.25
|| 323.0 | 9.0 | 314.0 | pe.29
|===========================================
/proc/self/statusを使う方法
各プロセスの使用リソースが記載されている/proc/self/statusの中のメモリに関する部分をジョブ実行中に参照・出力できます。
- VmRSS: 実メモリ使用サイズ
- VmHWM: 実メモリ使用サイズのピーク
- VmSize: 現在の仮想メモリ使用サイズ
- VmPeak: VmSizeのピーク値
ここでは物理メモリに確保されたメモリ量が知りたいので,VmRSSとVmHWMを出力します。
以下にC言語とFortranでの例を示します。この関数をソースコードの適切な場所に挿入すると,メモリ使用量を出力できます。
- C言語での関数例
- Fortranでのサブルーチン例
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
void print_mem()
{
char line[1000];
FILE *in_fh;
in_fh = fopen("/proc/self/status","r");
int vmhwm, vmrss;
while (fgets(line, sizeof(line), in_fh)) {
if (strncmp(line, "VmHWM:", 6) == 0) {
sscanf(line, "VmHWM: %d kB", &vmhwm);
} else if (strncmp(line, "VmRSS:", 6) == 0) {
sscanf(line, "VmRSS: %d kB", &vmrss);
}
}
printf("VmHWM: %d kB, VmRSS: %d kB\n",vmhwm,vmrss);
}
subroutine print_mem
parameter(lun=99)
character*80 line
integer(kind=8) hwm,rss
open(lun,file='/proc/self/status')
do while(.true.)
read(lun,'(a)',end=99) line
if(line(1:6).eq.'VmHWM:') read(line(8:80),*) hwm
if(line(1:6).eq.'VmRSS:') read(line(8:80),*) rss
enddo
99 close(lun)
print *,'VmHWM: ',hwm,'kB, ','VmRSS: ',rss,'kB'
return
end
2. XC50でのジョブ実行状況から推測した,XD2000のシステムMとPでのジョブ実行
XC50でのジョブ実行状況
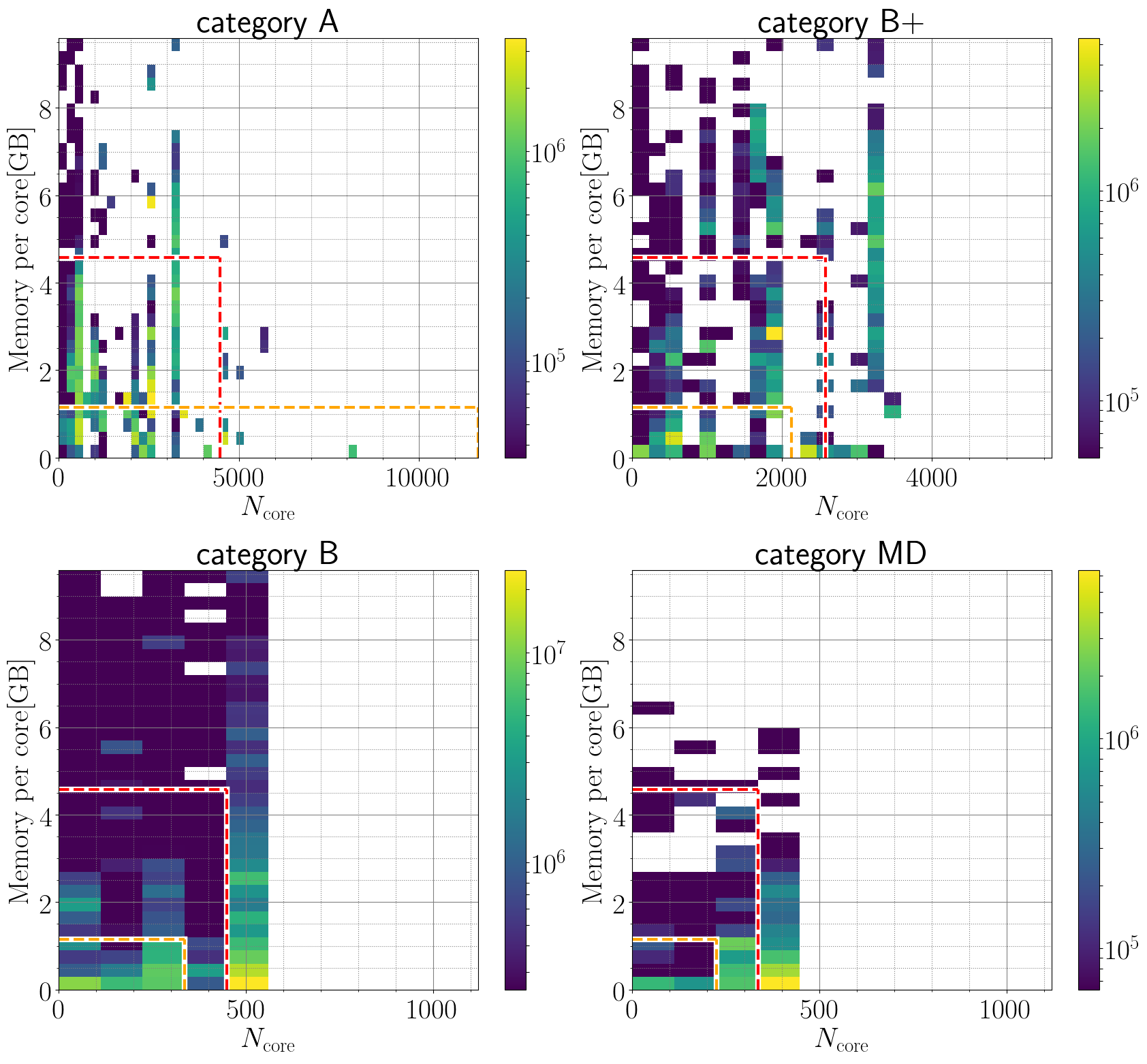
下図は,XC50で2023年度と2024年度(5月まで)に流れていたジョブの2次元頻度分布(コア数 v.s. コアあたりの使用メモリ量の平均値)です。使用メモリ量は各ノード毎に12時間に1回freeコマンドを実行し,usedの値として取得しています。ここで「各ジョブのコア当たりの使用メモリ量」とは,各ノードの使用メモリ量の時系列データの最大値を40で割った値です。オレンジ色と赤色で囲まれた領域が,それぞれコア数不変のままシステムMとPのlargeキューで流せるジョブに対応します。
- カテゴリAとB+
- 比較的コア数が少なく,かつ,大メモリを使用しているジョブが多く,コア数が不変であれば,システムMで走らないジョブが多いことがわかります。XD2000で流れるようにするには,コア数を増やす必要があります。
- 3000コア以上で大メモリ(>3GB/core)を使用しているジョブは,システムPでも流せません。
- カテゴリBとMD
- XC50での単一ジョブ最大コア数(Bでは520コア,MDは400コア)付近に,メモリ使用量が小さなジョブが集中しています。
XD2000で流れるようにするには,コア数を減らす必要があります。
- XC50での単一ジョブ最大コア数(Bでは520コア,MDは400コア)付近に,メモリ使用量が小さなジョブが集中しています。
システムMとPで流れると想定されるジョブの割合
システムMとPの計算資源の割合は,208ノード:80ノード=7:3です。したがって,システムMとPに,ノード時間積で測ったジョブの割合が7:3で配分されるのが理想です。
下図は,XC50で流れているジョブの中で,システムMとPで流すことのできるジョブの割合を,単一ジョブ最大コア数の関数として表しています。星印は現在のキュー構成での単一ジョブ最大コア数を示しています(ただしカテゴリAについては,現実的には単一ジョブ最大コア数では流れないので,カテゴリB+の単一ジョブ最大コア数にしています。)
流せるかどうかは,ノード当たりのメモリ量が各システムが搭載しているメモリ量を下回るかどうかだけで判断しています。
実線および破線は,それぞれ各ノードの使用メモリ時系列データの最大および平均をとった値で算出した場合に対応しています。淡色の線は,総メモリ量の70%を消費して(30%の余裕をもって)流すことができるジョブの割合を表しています。
- カテゴリAとB+
- コア数が少ない(単一ジョブ最大コア数が小さい場合の相当)には,ほとんどのジョブを流せなくなります。コア数(ノード数)を増やしてメモリ量を稼ぐ必要があります。
- 1割から2割程度のジョブがシステムPでも流れなくなることがわかります。
カテゴリAの場合は,システムPで∼4000コア(40ノード)使えれば,システムPで実行可能ですが,全ノード数の半分を使う必要がありますので,通常運用時には流れないと思われます。
- カテゴリBとMD
- コア数を減らせば,おおよそ7:3の割合で大部分のジョブはシステムMとPで流すことができると思われます。
- ただし5%程度のジョブはシステムPでも流せなくなります。→ P-large-b*キューの利用を検討してください。
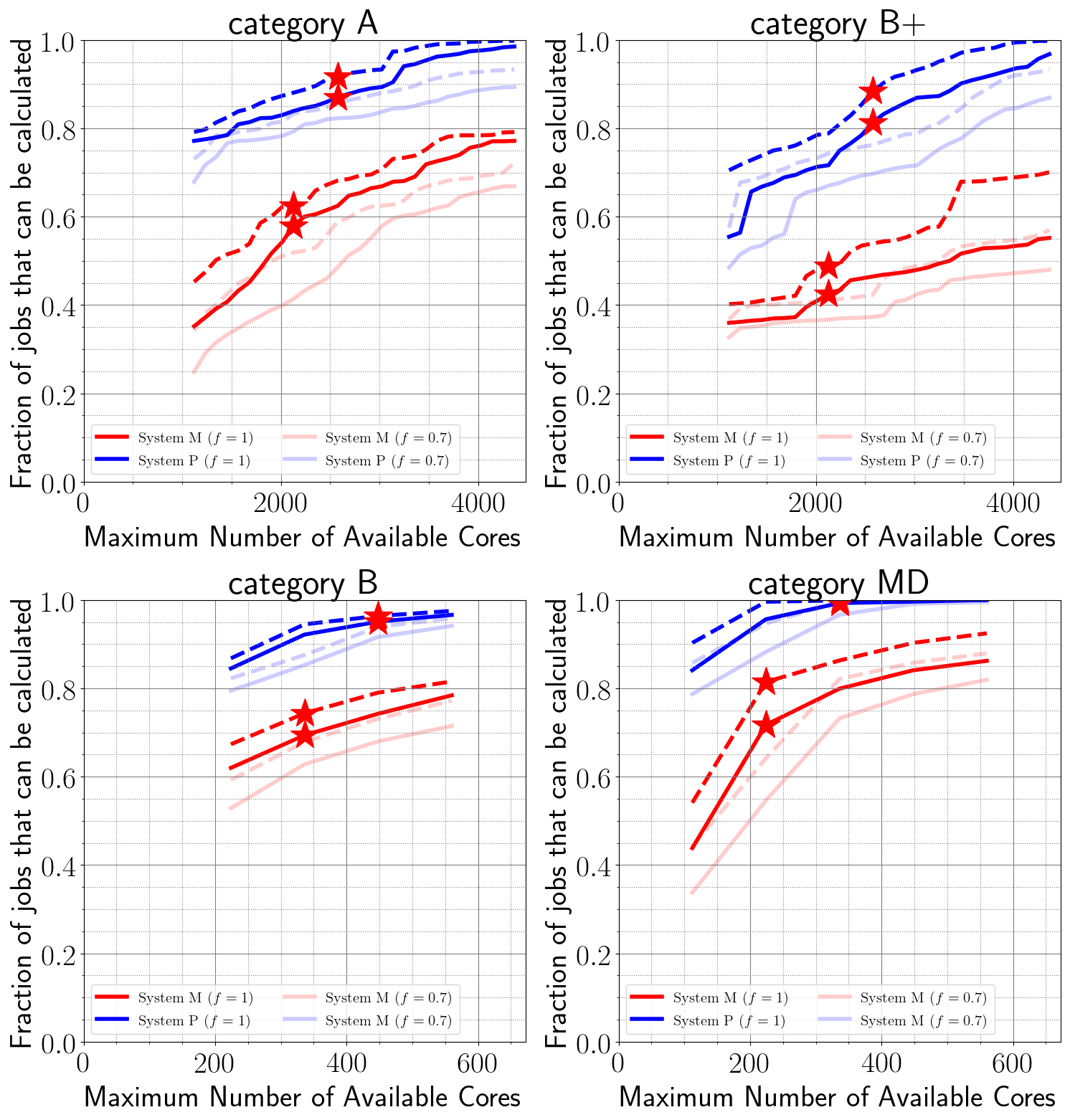
淡色の線は,総メモリ量の70%を消費して流すことができるジョブの割合を表しています。